
證券時(shí)報(bào)網(wǎng)
李勁
2025-02-21 18:49


北京時(shí)間2月18日,在馬斯克還在慶祝Grok 3模型正式發(fā)布的時(shí)候,DeepSeek官方在社交平臺(tái)X上發(fā)布了一篇純技術(shù)論文,主要是關(guān)于原生稀疏注意力(Native Sparse Attention,下稱(chēng)NSA),直指ChatGPT等頂尖大模型背后的Transformer架構(gòu)最核心的注意力機(jī)制。
通過(guò)這一技術(shù),DeepSeek不僅能將大語(yǔ)言模型處理64k長(zhǎng)文本的速度最高提升11.6倍,更在通用基準(zhǔn)測(cè)試中實(shí)現(xiàn)了對(duì)傳統(tǒng)全注意力模型(Full Attention models)的性能反超。
值得注意的是,這篇論文是由DeepSeek創(chuàng)始人梁文鋒親自提交的,而且他也是作者之一。而就在DeepSeek發(fā)表這篇技術(shù)論文的同一天,月之暗面創(chuàng)始人楊植麟也“掛帥”發(fā)布了最新論文,主題同樣圍繞長(zhǎng)文的算法優(yōu)化。
月之暗面提出的新方法叫塊注意力混合(Mixture of Block Attention,下稱(chēng)MoBA)。這項(xiàng)方法沒(méi)有完全脫離現(xiàn)在最主流的全注意力機(jī)制,而是設(shè)計(jì)了一套可以自由切換的方式,讓這些模型可以在全注意力和稀疏注意力機(jī)制之間切換,給已有的全注意力模型更多的適配空間。
談及DeepSeek的NSA機(jī)制,風(fēng)投公司RAI Digital聯(lián)合創(chuàng)始人薩義德·戈蘇斯對(duì)《每日經(jīng)濟(jì)新聞》記者解釋稱(chēng),與馬斯克所追求的“大力出奇跡”不同,DeepSeek的新技術(shù)更強(qiáng)調(diào)通過(guò)算法優(yōu)化來(lái)提升長(zhǎng)文處理效率。他提到,NSA不會(huì)專(zhuān)注每個(gè)單詞,而是嘗試通過(guò)只關(guān)注重要的單詞來(lái)提升效率。
DeepSeek發(fā)布新論文,梁文鋒參與并提交
北京時(shí)間2月18日,DeepSeek官方在X上發(fā)布新論文,介紹了一種新的算法優(yōu)化方式——原生稀疏注意力(NSA)。
據(jù)DeepSeek介紹,NSA專(zhuān)為長(zhǎng)文本訓(xùn)練與推理設(shè)計(jì),能利用動(dòng)態(tài)分層稀疏策略等方法,通過(guò)針對(duì)現(xiàn)代硬件的優(yōu)化設(shè)計(jì),顯著優(yōu)化傳統(tǒng)AI模型在訓(xùn)練和推理過(guò)程中的表現(xiàn),特別是提升長(zhǎng)上下文的推理能力,在保證性能的同時(shí)提升了推理速度,并有效降低了預(yù)訓(xùn)練成本。

圖片來(lái)源:X
通過(guò)這一技術(shù),DeepSeek不僅能將大語(yǔ)言模型處理64k長(zhǎng)文本的速度最高提升11.6倍,更在通用基準(zhǔn)測(cè)試中實(shí)現(xiàn)了對(duì)傳統(tǒng)全注意力模型的性能反超。

圖片來(lái)源:DeepSeek的X賬號(hào)
值得注意的是,DeepSeek創(chuàng)始人梁文鋒也出現(xiàn)在了論文作者的行列當(dāng)中,在作者排名中位列倒數(shù)第二,并且也是他親自提交至預(yù)印本網(wǎng)站上的。

圖片來(lái)源:arXiv
論文的第一作者是DeepSeek的實(shí)習(xí)生袁景陽(yáng),他于2022年在北大獲得了學(xué)士學(xué)位,目前在北大的Anker Embodied AI實(shí)驗(yàn)室繼續(xù)攻讀研究生學(xué)位。他也是DeepSeek-V3報(bào)告的主要作者之一,并參與了DeepSeek-R1的研究工作。
月之暗面再次“撞車(chē)”DeepSeek
無(wú)獨(dú)有偶,在DeepSeek發(fā)論文的當(dāng)天,月之暗面創(chuàng)始人楊植麟也親自“掛帥”發(fā)表了一篇論文,同樣直指算法優(yōu)化。

楊植麟 圖片來(lái)源:視覺(jué)中國(guó)

圖片來(lái)源:月之暗面
該公司提出的新方法叫塊注意力混合(MoBA)。顧名思義,這一方法也運(yùn)用了將詞變成塊的方法。不過(guò),該方法沒(méi)有完全脫離現(xiàn)在最主流的全注意力機(jī)制,而是設(shè)計(jì)了一套可以自由切換的方式,讓這些模型可以在全注意力和稀疏注意力機(jī)制之間切換,給已有的全注意力模型更多的適配空間。
根據(jù)論文,MoBA的計(jì)算復(fù)雜度隨著上下文長(zhǎng)度增加而優(yōu)勢(shì)明顯。在1M token的測(cè)試中,MoBA比全注意力快了6.5倍;到10M token時(shí),則提速16倍。而且,它已經(jīng)在Kimi的產(chǎn)品中使用,用來(lái)處理日常用戶(hù)們的超長(zhǎng)上下文的處理需求。
而這也并不是是DeepSeek和月之暗面第一次“撞車(chē)”了,上一次是在DeepSeek推理模型R1和月之暗面推理模型Kimi 1.5發(fā)布時(shí)。
MoBA論文主要作者章明星教授笑稱(chēng),“有種‘掌中,亦一火字’的感覺(jué)(不討論誰(shuí)是孔明,誰(shuí)說(shuō)周郎)。”他同時(shí)也感慨:“大模型這套架構(gòu)最神奇的一點(diǎn)我感覺(jué)就是它似乎自己就指出了前進(jìn)的路線(xiàn),讓不同的人從不同的角度得出了相似的前進(jìn)方向。”
DeepSeek新方法背后的三大技術(shù)
談及DeepSeek的新方法,風(fēng)投公司RAI Digital聯(lián)合創(chuàng)始人薩義德·戈蘇斯告訴每經(jīng)記者,這是AI模型處理超長(zhǎng)文本的新方法,比傳統(tǒng)方法更快、更高效。
像ChatGPT這樣的大型語(yǔ)言模型,都使用一種叫“注意力”(Attention)機(jī)制的方法來(lái)處理文本,2017年谷歌研究員推出的論文《Attention Is All You Need》被認(rèn)為是現(xiàn)在所有大模型的基石。
戈蘇斯進(jìn)一步向每經(jīng)記者解釋道:“想象一下你正在讀一本書(shū)。要理解一個(gè)句子,你不僅要看當(dāng)前的單詞,還要回憶起前面句子中的相關(guān)單詞,以理解所有內(nèi)容。AI使用注意力做類(lèi)似的事情,這有助于它確定哪些詞是重要的,以及它們彼此之間的關(guān)系。傳統(tǒng)注意力機(jī)制(全注意力)會(huì)查看文本中的每個(gè)單詞,并將其與其他每個(gè)單詞進(jìn)行比較。這對(duì)于短文本來(lái)說(shuō)很好,但是當(dāng)文本很長(zhǎng)時(shí)(比如整本書(shū)或一份長(zhǎng)的法律文件),這個(gè)過(guò)程就會(huì)變得太慢,而且在計(jì)算機(jī)上運(yùn)行成本太高。
而DeepSeek論文中提到的稀疏注意力機(jī)制不會(huì)專(zhuān)注每個(gè)單詞,而是嘗試通過(guò)只關(guān)注重要的單詞來(lái)提升效率,就像是只讀摘要而不是整本書(shū)一樣。
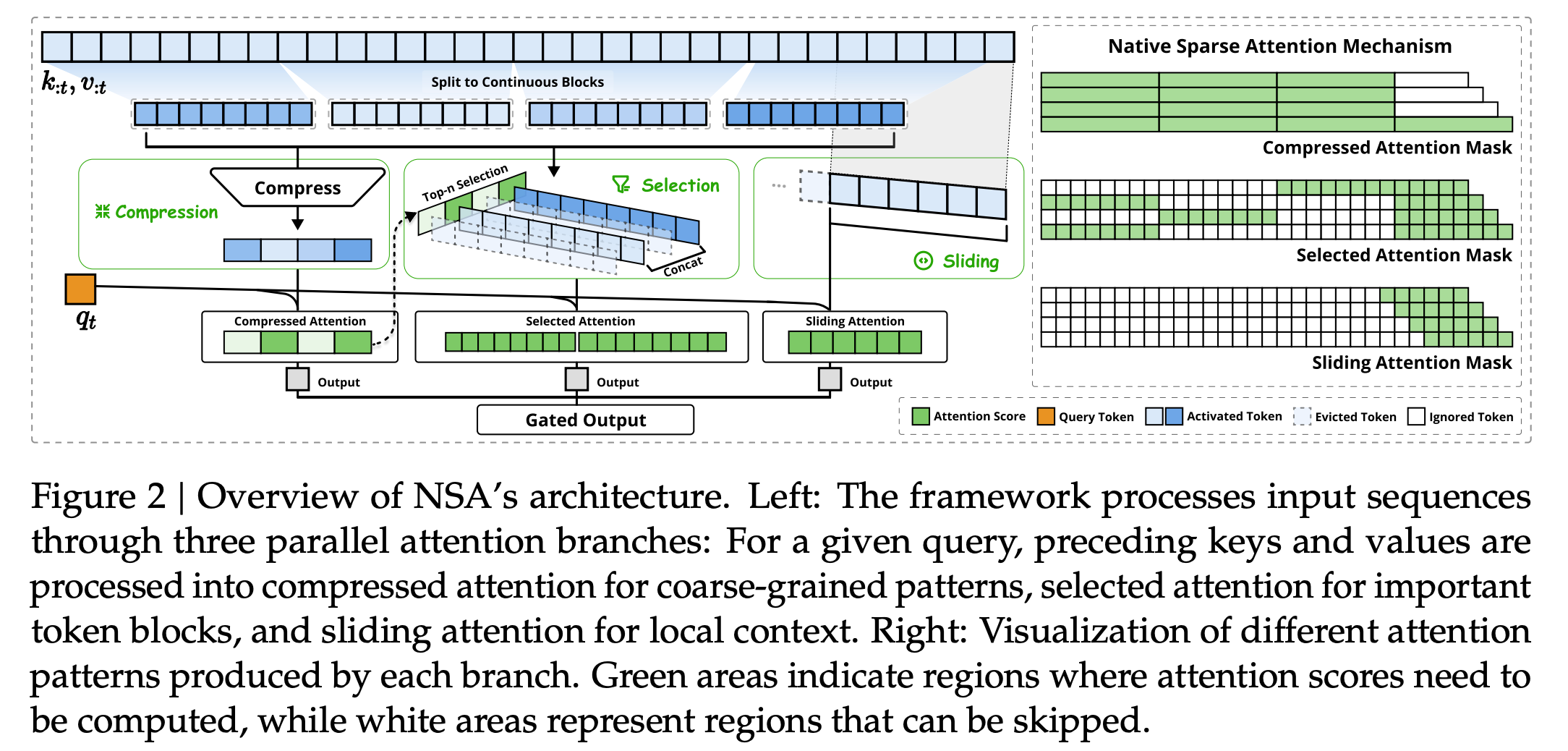
戈蘇斯對(duì)每經(jīng)記者介紹說(shuō):“為了做好這一點(diǎn),NSA引入了一種新方法來(lái)過(guò)濾不重要的單詞,同時(shí)仍保留足夠的上下文來(lái)理解完整含義。
它使用三種主要技術(shù)來(lái)實(shí)現(xiàn)這一點(diǎn):
壓縮:NSA不會(huì)查看每個(gè)單詞,而是將單詞分組為“塊”,并為每個(gè)塊創(chuàng)建摘要。可以將其想象成將一個(gè)段落變成一個(gè)簡(jiǎn)短的摘要。
選擇:模型從文本中挑選出最應(yīng)該關(guān)注的重要單詞。就像在學(xué)習(xí)時(shí),只突出顯示教科書(shū)中的關(guān)鍵句子一樣。
滑動(dòng)窗口:盡管NSA總結(jié)并選擇了單詞,但它仍然會(huì)查看附近的單詞,以確保不會(huì)錯(cuò)過(guò)細(xì)小但重要的細(xì)節(jié)。想象一下閱讀一本書(shū)——人們不會(huì)只是從一頁(yè)跳到下一頁(yè)而不瀏覽附近的句子。
DeepSeek認(rèn)為,三部分策略使NSA速度更快,同時(shí)理解含義的能力與傳統(tǒng)方法一樣好(甚至更好)。”
圖片來(lái)源:DeepSeek
有網(wǎng)友稱(chēng),這是在教會(huì)AI學(xué)會(huì)“聰明的偷懶”,像人類(lèi)一樣聰明地分配注意力,從而讓長(zhǎng)文的處理又快又準(zhǔn),不再是一個(gè)“死讀書(shū)的呆子”。雖然犧牲了一定的準(zhǔn)確率,但是極大提升了效率,人腦就是這么干的。
戈蘇斯還表示,DeepSeek這次不僅是單純的算法進(jìn)步,它還對(duì)現(xiàn)有的計(jì)算機(jī)硬件進(jìn)行了優(yōu)化,以便GPU可以實(shí)現(xiàn)有效處理。
有科技媒體指出,DeepSeek此次使用了Triton框架,而非英偉達(dá)專(zhuān)用庫(kù),這或許暗示了其在模型研發(fā)階段已考慮適配更多類(lèi)型的計(jì)算卡,為未來(lái)的開(kāi)源和廣泛應(yīng)用奠定了基礎(chǔ)。






